While typing this blog post, I’m flying back from the Data Platform Next Step conference where I gave a talk about using dbt with Microsoft Fabric . DP Next Step was the first conference focussed on Microsoft data services right after the announcement of Microsoft Fabric so a lot of speakers were Microsoft employees and most of the talks had some Fabric content.

Fabric Fabric Fabric, what is it all about? In this post I’ll go deeper into what it is, why you should care and focus specifically on the SQL aspect of Fabric.
Not so curious about why I think Fabric is the best thing to happen in the Microsoft data ecosystem? This is the TL;DR of this post:
- All data, however you create it, is stored in a data lake called OneLake
- No more copying data, just link the data you already have
- Fabric uses the popular open-source Delta format
- Fabric decouples storage and compute
- Fabric can scale automatically and can scale to 0
- Fabric is a true lakehouse and was built for the cloud
- The cheapest pricing tier for Fabric is more than 5x times cheaper than Synapse > Dedicated SQL
- Fabric does not build upon Synapse Dedicated SQL and this will soon be the “previous generation”
- Fabric is expected to go live near the end of 2023 with a public preview available for free
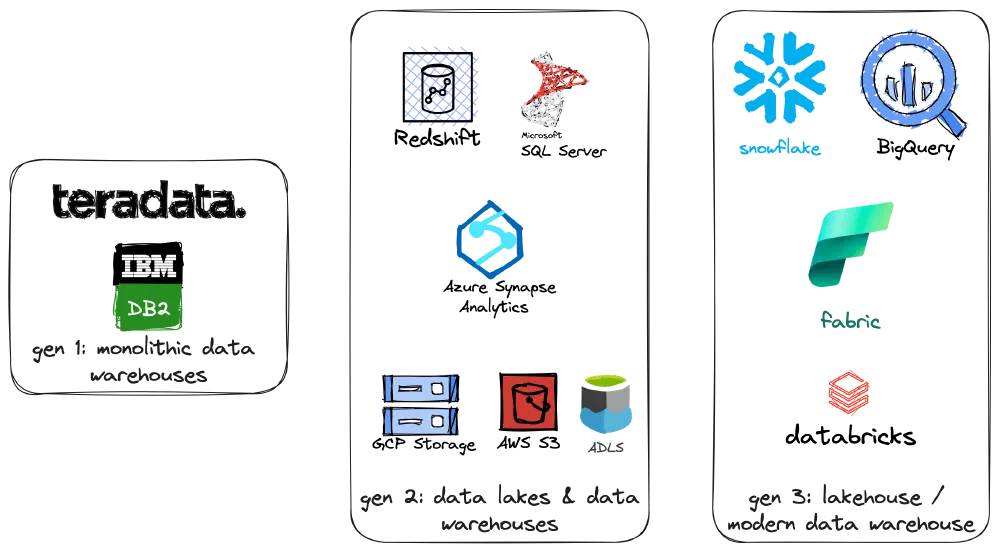
As the title says, one of the components of Fabric is Microsoft’s first third-generation data warehouse. “Third” means there must be two generations before it, right? Let’s take a look at those first.
First generation: Teradata and friends
In the nineties, the first data warehouses appeared. With them, came the concept of dimensional modeling (Kimball published The Data Warehouse Toolkit in 1996). While these were good at the time, it doesn’t make much sense to use these monolithic slow giants today.
Second generation: Azure SQL Data Warehouse, Azure Synapse…
Then the second generation of data warehouses came along. Microsoft acquired Parallel Data Warehouse and released it as a layer on top of Microsoft SQL Server in 2010. They put a lot of effort into making the MPP (Massive Parallel Processing) engine a good fit for big data. In 2016, this engine (the version from SQL Server 2016) was brought into the cloud as Azure SQL Data Warehouse. This was then called the second generation.
In 2019, this product was rebranded to Azure Synapse Analytics Dedicated SQL Pool. While the rebranding made it seem like this was an entirely new product, we were still working with that same technology. Again, at the time of its introduction, this was a good option. It already made less sense at the time of its rebranding though.
You’re wondering why? This is what you have to think of when you’re using the Dedicated SQL Pools:
- All data is split into 60 “partitions”. This can be used to parallelize the workload onto multiple nodes in a cluster. The way it is split into those nodes is determined by the distribution option you choose for your table.
- The pricing was based on the number of DWUs (Data Warehousing Units). It started at 100 DWUs for about 1000 USD per month and went up from there. At 500 DWUs this translated to a single node handling all the partitions. At 1000 DWUs, you had two nodes, each handling 30 partitions. At 2000 DWUs, you had four nodes, each handling 15 partitions. And so on. Everything below 500 DWUs meant that you only had a fraction of the capacity of a single node.
- Next to distribution settings, indexing settings also impacted the performance of your data warehouse quite a lot.
- Scaling up and down, and spinning up new data warehouses is an intensive operation. This takes your data warehouse offline for several minutes.
- You have to clearly define workload management rules to make sure that your data warehouse doesn’t get overloaded. It is hard to optimize them to use the provisioned capacity to the fullest.
- The supported T-SQL area was not consistent with what users were used to in SQL Server.
This gave a lot of users, including myself, a lot of headaches.
Third generation: Snowflake, Fabric…
At the time of the Synapse rebranding, the third generation of data warehouses was already there. The most popular one is Snowflake . It is a cloud-native data warehouse that is built from the ground up to be scalable and easy to use. Snowflake decouples compute and storage and easily handles big workloads without having to tinker with distribution settings and indexing.
Note that you should still look at partitioning and indexes when you want to gain the most optimal performance. The necessity is just a lot lower and scaling goes a lot easier.
At the same time as the rebranding to Azure Synapse, Microsoft also released Azure Synapse Serverless SQL Pools. This was the first product with glimpses of the Polaris engine which Microsoft published a paper about in 2020. If you want to learn more about what’s underneath Synapse and Fabric, I’d definitely recommend reading it.
In Synapse, the serverless pools can only perform SELECT statements and build views. This might be enough for a large user base, but most data analysts like to run things like CTAS (Create Table As Select) to persist data in a new table so that their reporting workloads run instantly.
This is where Microsoft Fabric comes in. The warehouse and lakehouse features in Fabric are feature-full data warehouses with decoupled storage and compute, automatic and easy scaling, distributed processing without any hassle and a lot more.
While the warehouse and lakehouse features are branded as Synapse Warehouse and Synapse Lakehouse, they only refer to the serverless pools in Synapse.
Modern data warehouse = lakehouse

All big vendors in the data landscape - Snowflake, Databricks, Microsoft, Starburst…- are moving in the same direction: the lakehouse.
After the era of the first data warehouses, a lot of folks moved to data lakes with Hadoop. This could decouple your storage from your computation engine so that they can be scaled individually and connecting to cheap cloud storage was easy. The learning curve and complexity of Hadoop were quite high though. People missed the simplicity of SQL.
The lakehouse is the best of both worlds. It is a data lake with a SQL engine on top of it.
In Fabric, all data is stored in the OneLake. There is only one OneLake. It might seem obvious, but this is a big difference from previous products where you could build multiple data lakes, and multiple data warehouses and linking them together was hard.
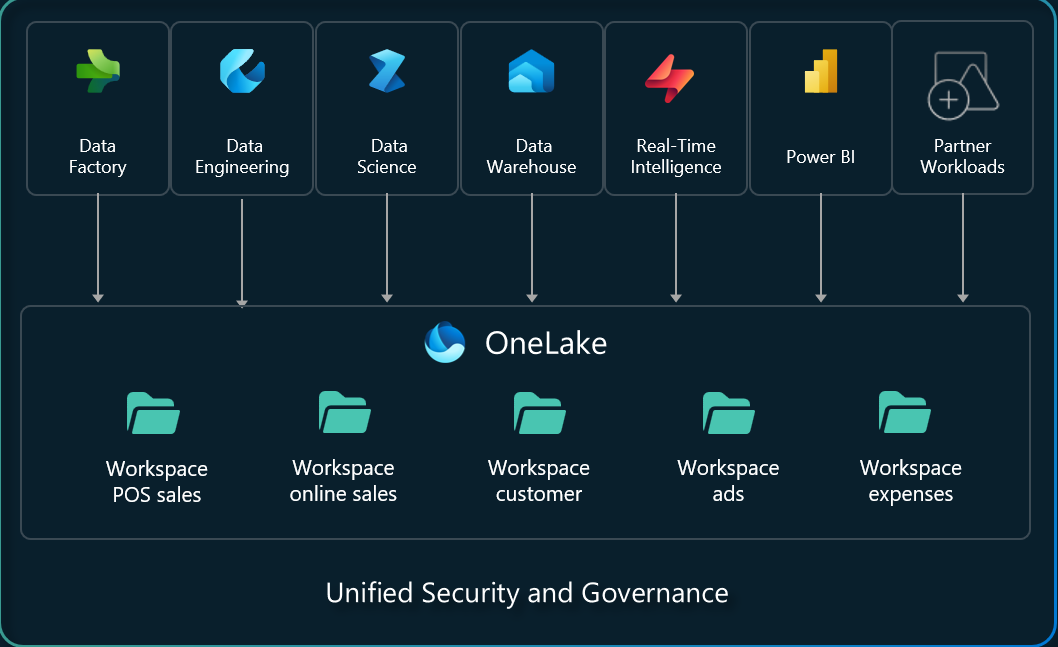
Everything you do in Fabric, will ultimately end up as delta tables in your OneLake. Delta is an open-source format that adds a transaction log to Parquet. It was built by Databricks and is used in their lakehouse product named Databricks SQL Warehouses. Delta enables you to do things like time travel, schema enforcement, ACID transactions and more.
To be clear, everything you do becomes a delta table which you can query with any compatible tool in the OneLake. Even creating tables in your Fabric Data Warehouse will create a delta table in the OneLake.
This is just awesome. It is open, simple, easy to use and straightforward.
Taking away the confusion: Fabric & Synapse SQL
Synapse SQL is the branding that Microsoft uses for its analytics-focused SQL efforts. Just by looking at the branding itself, you might rationally think that Synapse Serverless SQL evolved into the Fabric Synapse Lakehouse and that the Synapse Dedicated SQL evolved into the Fabric Synapse Warehouse. While the first one holds some truth, the latter doesn’t.
Synapse Dedicated SQL Pools are the second generation data warehouses based on Parallels Data Warehouse and there is no trace of it in Fabric. The Fabric Synapse Warehouses is the same engine as the one which powered Synapse Serverless SQL but then with a warehouse-like experience.
| Current name | On-premise version | Previous name(s) | Engine |
|---|---|---|---|
| Azure Synapse Analytics Dedicated SQL Pool | Parallel Data Warehouse | Azure SQL Data Warehouse | MPP |
| Azure Synapse Analytics Serverless SQL Pool | N/A | - | Polaris |
| Synapse Lakehouse (part of Fabric) | N/A | - | Polaris |
| Synapse Warehouse (part of Fabric) | N/A | - | Polaris |
OneLake shortcuts
With OneLake, Microsoft also introduced the concept of the single copy. You don’t have to copy data from your Microsoft Sharepoint, Azure ADLS, AWS S3 or GCP GCS data lakes to use them, you can just create Shortcuts. These are a sort of logical links that just point to your data and the Fabric engines can directly connect to them.
This is not confirmed, but my expectation is that Microsoft will soon add the capability to link more existing data sources like Azure SQL, DataVerse, and more.
Fabric engines
Interacting with the OneLake can be done with multiple engines, whichever works best for you and your team.
Do you like writing Spark code? Great! It has a Spark engine, an interface with notebooks, you can submit and schedule Spark jobs, install packages in your clusters…
Do you prefer to stick with SQL? Awesome! The SQL endpoint in the lakehouse experience allows you to query all of your data with SQL.
Do you love to build data warehouses? Cool! The data warehouse experience offers a fully-fledged data warehouse where each table automatically becomes a dataset in your OneLake.
Do you like to use Power BI? Nice! You can connect to the SQL endpoint and build your reports.
Anything which supports the regular T-SQL interface is supported as well, hence the dbt support I briefly mentioned above.
Linking any of your lakehouses, warehouses or Spark-created tables together is easy peasy lemon squeezy. You can even query them together in a single query.
Pricing
The pricing overview might seem daunting at first and might also still change. Right now, Fabric is free to use. Everyone can start a free trial and play with it as much as they’d like for the coming months.
After that, you can either buy Power BI Premium capacities or Azure Fabric capacities. These capacities dictate both the maximum performance as well as the region in which your data will reside. Note the maximum performance in that sentence. Fabric can scale down to zero and you only pay for what you use. This is a big difference from the previous generations where you had to pay for the full capacity even if you didn’t use it. Billing is per second and rounded up to the nearest minute.
You can get started with Azure Fabric capacities for as low as a few hundred USD per month. This is a lot cheaper than the previous generations.
On Databricks, Power BI, and Microsoft Excel
You might think “Wait, we already have a great lakehouse product on Microsoft Azure: Databricks!” And you’re 100% correct. You could even say that in some ways Databricks resembles Fabric closer than Synapse. As both Databricks and Fabric are lakehouses built upon Delta lakes, they both achieve the same goal but in different ways.
Fabric is encapsulated in the Microsoft Power BI suite of tools and focuses on bringing analytics closer to the business users who use Power BI today. Hell, even bringing your Fabric datasets to Excel is incredibly easy. Pivot tables from your Fabric lakehouse table? Only a few clicks away! You cannot argue with this. Microsoft Excel and Power BI are the most used data tools today, by far. It makes a ton of sense to look at it from this perspective.
Microsoft had 35 times more Power BI users than Azure Synapse users.
Databricks, on the other hand, is the company that was founded by the creators of Apache Spark. They have a code-first mentality with excellent support for Infrastructure as Code toolings like Terraform, CI/CD deployments, containerized workloads, MLflow and so much more. This is just a different audience. Data engineers will feel right at home in Databricks.
The caveat
Fabric is still in preview with a go-live expected near the end of this year. This means that there are still some rough edges and quite some missing features. Microsoft has some work to do to make it a fully usable product and deliver on its promises.
I’ve been working with Fabric as part of the private preview for about half a year now and I saw it continuously evolve with new features and fixes arriving about every week. Given the dedicated publicity and marketing efforts, I’m confident we will soon live in 3rd generation data world.
