Last week I attended Big Data London . Both days were filled with interesting sessions, mostly focussing on the vendors also exhibiting at the conference. There are 2 things I am taking away from this conference:
- Delta Lake has won the data format wars
- Your next data platform is either Snowflake, either an open Lakehouse


You might be surprised to not see Generative AI in there, but I feel that this has become such an overarching topic, present in everything we do on our computers these days. Of course, it’s going to make us more productive. Of course, it’s going to make technology more approachable to less tech-savvy users. Of course. But that isn’t news anymore today. It would be a shame if you’re building a new software solution today and it didn’t leverage the power of an LLM.
Delta Lake has won the data format wars
![]()
These days, more often than not, you’ll store your data in some kind of object storage, or a data lake. The question you’re asking yourself next is: which format should I pick? After all, you’d like to write your data only once and never have to think about it again. Rewriting all existing data to another format can be a costly operation.
Is Parquet still the way to go? The answer would always be yes and no. Data is still stored in Apache Parquet. It’s the most efficient way to store data meant for analytics which is often doing columnar aggregrations. But just plain Parquet by itself is no longer enough.
When you’re looking at the limitations of Parquet, you’ll find:
- no support for ACID transactions: when multiple processes are writing data at the same time, the output is non-deterministic.
- usually your only 2 options to write data are completely overwriting existing datasets or appending new data to it without any checks for duplicates.
The data community has come up with a few different solutions to tackle these issues:
- Delta Lake : a project created by Databricks , now part of The Linux Foundation . Mostly seen in Databricks and other Spark-based platforms.
- Apache Iceberg : a project founded by Ryan Blue and Dan Weeks (both Netflix) and part of the Apache Sofware Foundation since 2018 .
- Apache Hudi : a project founded by Vinoth Chandar (Uber) who built Onehouse to commercially support its development through the Apache Software Foundation .
They all basically do the same thing: add a transaction log next to the Parquet files. They all have full compabitiblity with regular Parquet and there is no difference at all in how the data is stored. The formats only differ in how they write their transaction logs and offer features like data time travel.
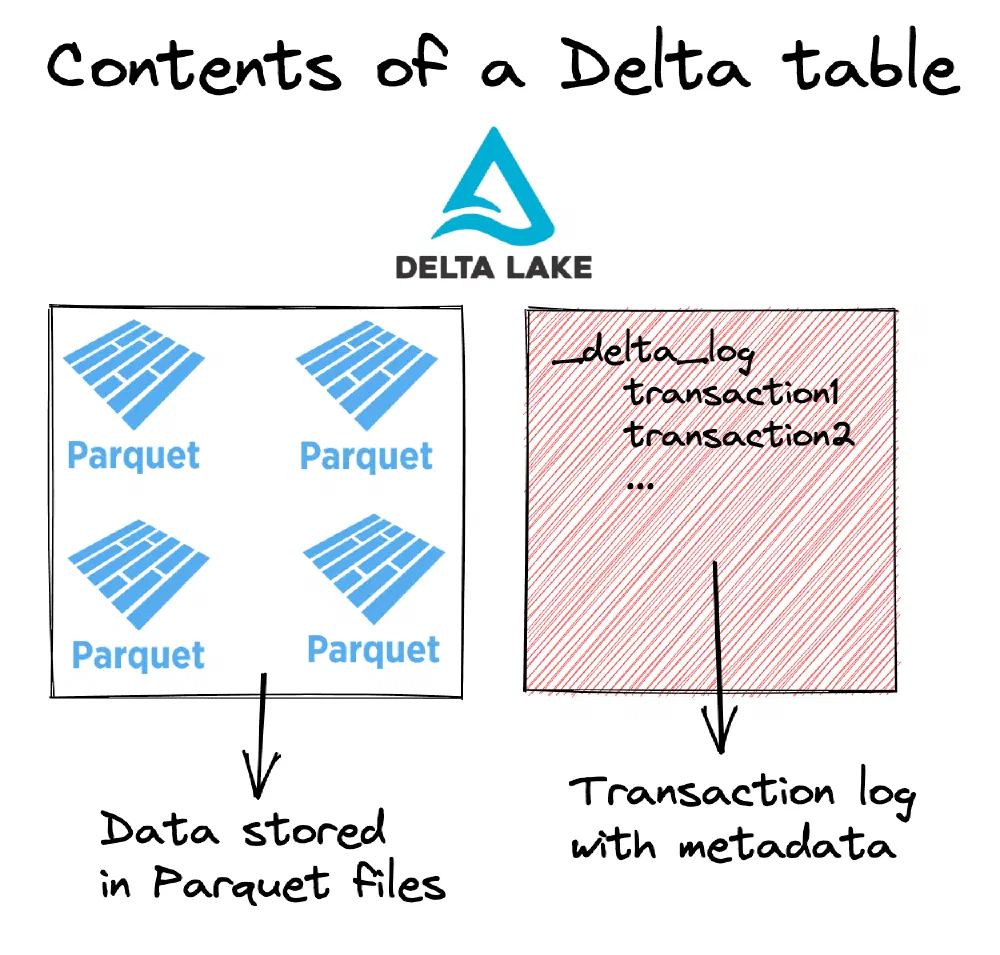
The common question up for debate then usually became: which one do you pick? The answer is clear now: Delta Lake. By talking to tens of vendors and attending an a dozen talks at Big Data London, Delta Lake was the common format that most of vendors supported. Often, some supported Iceberg or Hudi as well, but often then that also came with limitations where not all the vendor’s product’s features were available.
If that’s not enough for a reason to choose for Delta Lake, then their new UniForm feature definitely is. Databricks announced this at their yearly DATA+AI Summit and beta support is rolling out right now . With UniForm, Delta Lake can write the transaction logs for Hudi and Iceberg as well. This makes it possible to write your data in Delta Lake and then read it with any other tool which only supports Iceberg and/or Hudi. So by enabling UniForm for your data, you’re making sure that you’ll never be facing compatibility issues.
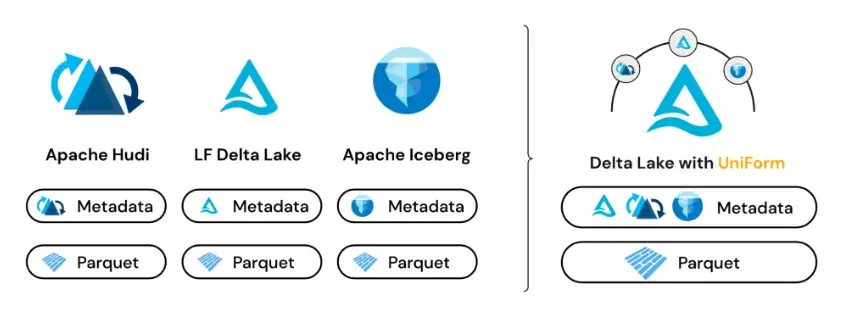
The open lakehouses
Another takeaway from the conference and from the online data community in general is the big push towards open lakehouses. Snowflake is dominating the market with its easily scalable data warehouse built for the cloud. They do an excellent job at separating compute and storage and making that easily accessible. The main disadvantage though is that Snowflake is not open. But what does it mean to be open?
Open infrastructure
Let’s compare the deployment of Databricks and Snowflake on Microsoft Azure. When you want to deploy Databricks, you connect to one of Azure’s deployment options (Azure Portal, Azure CLI, bicep, Terraform, …) and deploy a new Databricks Workspace. The deployment automatically creates a second Azure Resource Group where it stores all the required infrastructure to run your data processing operations. What is kept secret from you, the user, is the SaaS product powering the Databricks Workspace and Control Plane.
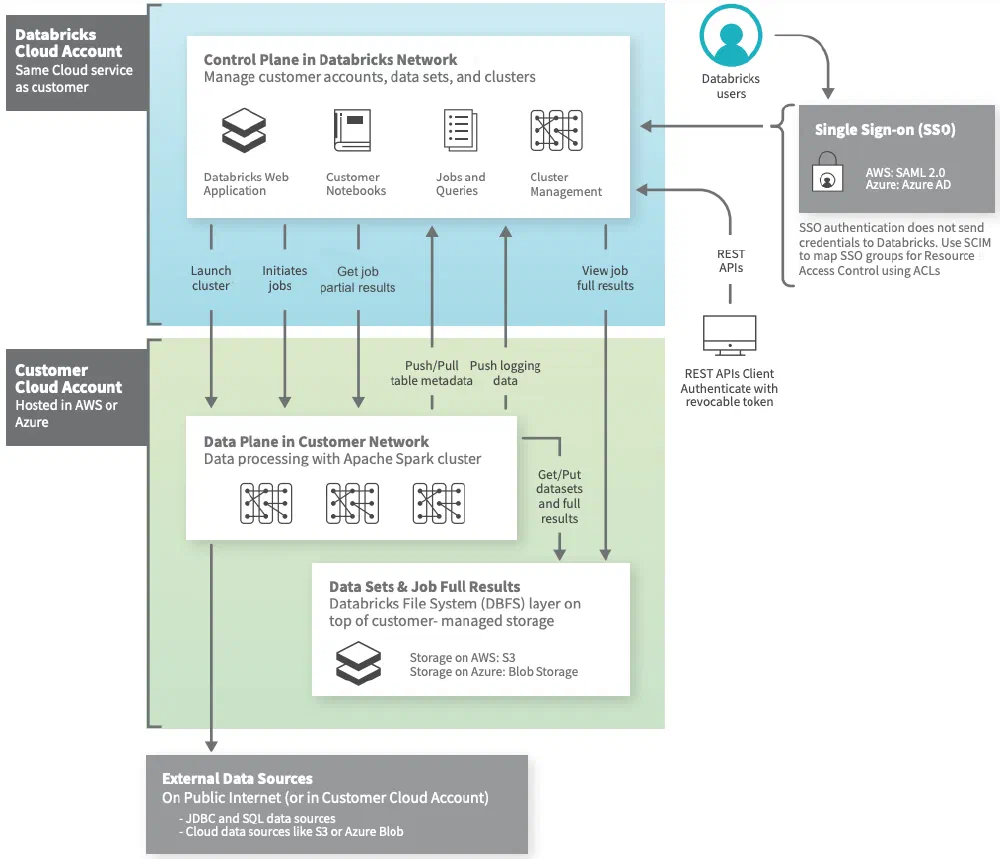
When you want to achieve the same thing for Snowflake, you won’t even find Snowflake anywhere in your regular Azure deployment options. Snowflake can only be deployed using its own tooling and website. During deployment, you get the option to choose the cloud provider (Azure, AWS, GCP) and region. At no point in time, you gain any access to the infrastructure processing your data.
Open software
So, infrastructure is one point where a data warehouse can be open. Another point is the software itself. Let’s analyze the available of sources for a few of Snowflake’s competitors:
- Databricks : built upon and still maintaining Apache Spark , Jupyter Notebooks , mlflow , and Delta Lake
- Microsoft Fabric : built upon Apache Spark , Jupyter Notebooks , mlflow , and Delta Lake
- Starburst : built upon and still maintaining Trino
- Dremio : the company actively supports and co-maintains Apache Arrow , Apache Arrow Flight , and Apache Iceberg. They also open sourced their data catalog Nessie . Their product is also available as an open-source version .
Open data storage
The last point that matters when it comes to openness in the data space is how data is stored. The competitors mentioned above are all compatible with Delta Lake (see part 1 of this post) and some support other formats like Iceberg or Hudi. At any point in time, you have full and direct access to your data in an open-source data format. You can monitor and manage the infrastructure where your data is stored and all of those solutions allow you to store your data in your own Azure or AWS cloud resources.
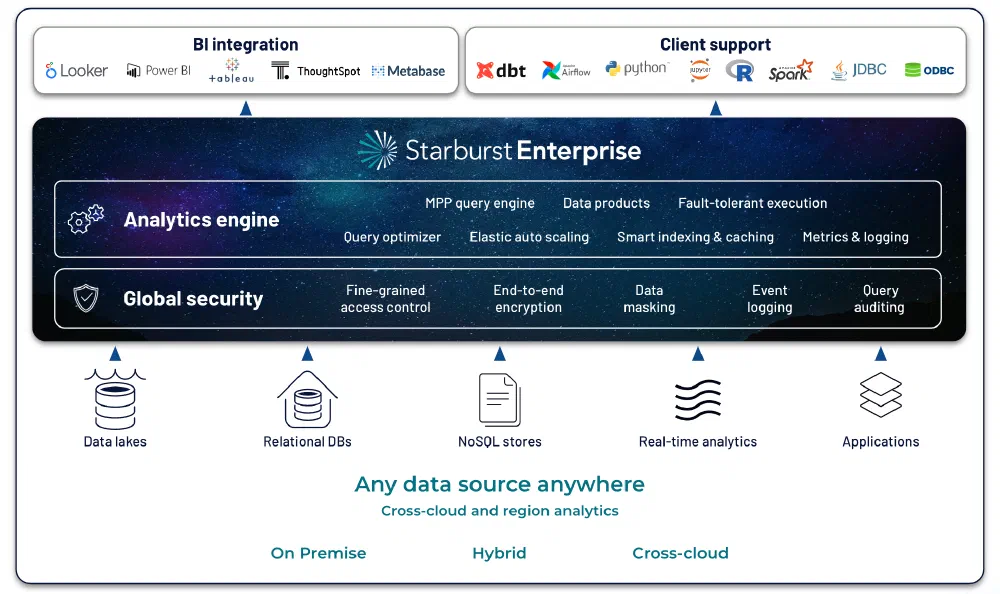
A great example of how it does not matter how and where your data is stored, is Starburst:
Open: conclusion
It’s clear that the openness is a big point for Snowflake competitors and I can only applaud that 👏. When we all share knowledge and offer compatibility, we all win. The first step to being open is by clearly separating data storage from the compute capacity provided by the vendor and this is something they all do. Therefore, the lakehouse design paradigm makes most sense for the Snowflake competitors. You can observe how much openness matters to these vendors by just looking at how they position their products:


It’s an exciting time in the data platform landscape. Competition and openness drive innovation. It’s time to think big.
