It’s a question I see popping up every now and then. Is Microsoft Fabric just a rebranding of existing Azure services like Synapse, Data Factory, Event Hub, Stream Analytics, etc.? Is it something more? Or is it something entirely new?
I hate clickbait titles as much as you do. So, before we dive in, let me answer the question right away. No, Fabric is not just a rebranding. I would not even describe Fabric as an evolution (as Microsoft often does), but rather as a revolution! Now, let’s find out why.
I’ve covered several bits and pieces of Microsoft Fabric in previous blog posts, so click this tag link to see all of them. Let’s use this post to look at the bigger picture, while also going into enough detail to understand how Fabric works and what’s under the hood.
The main structure
Fabric’s features are centered around Experiences. At the time of writing, the following are available:
- Power BI
- Data Factory
- Data Activator (Private Preview only)
- Synapse Data Engineering
- Synapse Data Science
- Synapse Data Warehouse
- Synapse Real-Time Analytics

All of those experiences each map to a certain subset of features that you’re free to mix and match however you’d like. This is how Fabric is presented to you, as a user.
This mixing and matching works flawlessly because of the common storage layer driving all of them: OneLake. This shared storage layer is the foundation of Fabric and allows you to work with your data consistently across all experiences.
But under the hood, Fabric is centered around a set of engines, which each talk to OneLake. These engines (at the time of writing) are:
- Analysis Services (e.g. Power BI DirectLake, DataFlow Gen2, …)
- Lakehouse / Apache Spark
- T-SQL: Lakehouse SQL Endpoint & Data Warehouse
- KQL
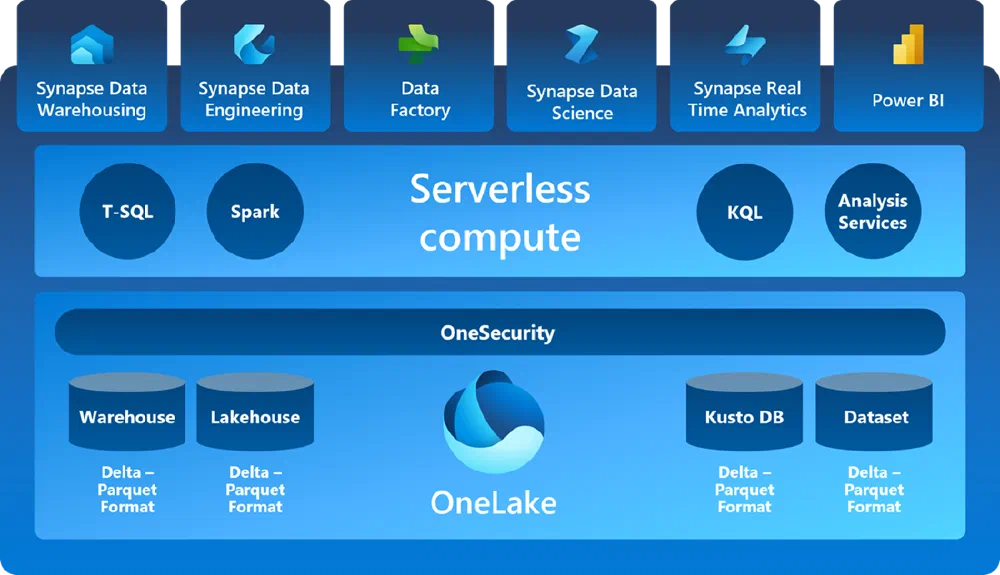
Okay, so now that we have a high-level overview of the main structure, let’s dive into the details of each of these engines.
OneLake: rebranding from ADLS Gen2?
Let’s start with the glue that holds everything together. How does OneLake compare to a regular Azure Storage Account with Hierarchical Namespaces enabled (Azure Data Lake Storage Gen2)?
The first difference is in the amount. You only have a single OneLake for your entire organization versus lots of different storage accounts. This removes the burden of the extra management and the ability to dial in every knob and switch to your liking.
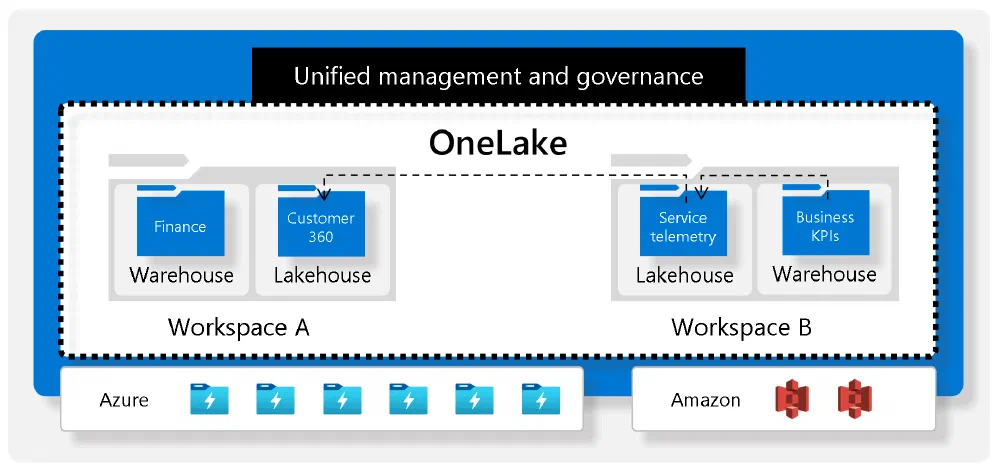
But what do you get in return? OneLake’s main feature is that you can easily link your existing data into OneLake using Shortcuts. This allows you to make logical links from existing data sources (Azure Storage Accounts, AWS S3, Microsoft Dynamics DataVerse, …) without having to ingest any data.
As I detailed in my post about billing for Fabric , OneLake’s pricing matches with ADLS gen2 with ZRS redundancy.
Analysis Services: rebranding from Power BI, Data Factory, Synapse Pipelines?
Under the Analysis Services, I would categorize features like the Data Pipelines, DataFlow Gen2, and Power BI’s DirectLake. I don’t know if that is also how Microsoft pictured that in the image above, but this is what makes sense to me.
Data Pipelines
Data Pipelines are not a new feature. We’ve had this functionality in Azure Data Factory (ADF) V2, Azure Synapse Pipelines, and now also in Fabric. From conversations with Microsoft, I understood that the goal is to bring most of the features from ADF to Fabric as well. I personally don’t think they will bring things like SSIS support, but rather focus on all the different connectors.
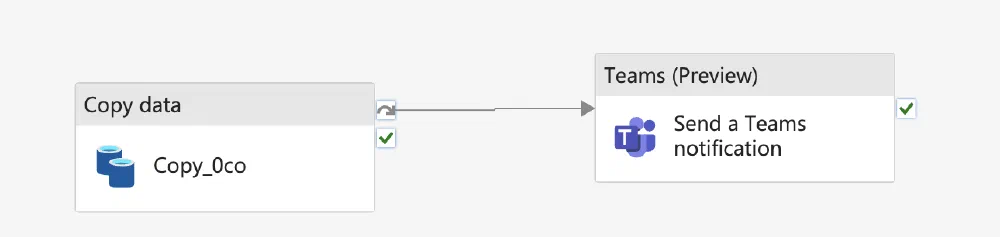
So, just a rebranding then? No, they made lots of changes to how you work with the Pipelines. You don’t have to define the ADF Datasets anymore, you don’t have to mess with Linked Services, you get new features such as secure variables and the Teams and Email connectors for easy notifications, … Under the hood, it all probably works in exactly the same way as before, but how it is exposed to the user makes much more sense to me. In my opinion, it looks like Fabric is going to be the best place to work with Data Pipelines in the future.
DataFlow Gen2
DataFlow Gen2 is the successor of the Mapping Data Flows in ADF, but it seems to be an entirely new thing. It’s based on Power Query, which already exists in Power BI, Microsoft Excel, and a few other Microsoft services. Is this just a rebranding then? I’d argue mostly yes, if you’re coming from Power BI Desktop. But at the same time, as a macOS user, I never had this functionality available as Power BI Desktop only exists for Windows. So for a lot of users, this will be a completely new thing as it’s now also available on the web. I know, it already existed in ADF as well, but not to this extent. We seem to be getting a much more complete experience now.
Power BI DirectLake
This is a really cool and completely new thing. Why is DirectLake so much better than Power BI reading Parquet files as before? I’d recommend to watch the video below.
In the video above, Bogdan Crivat, currently VP of Synapse Analytics and co-author of Vertipaq, the query processing engine powering Power BI, explains how Vertipaq can be leveraged in the processing of Delta Lake (Parquet) files from OneLake. Both storage systems have similar features and the OneLake Delta Lake data can be transcoded into Vertipaq’s native format. This allows for much faster processing of the data, than what we had with the old Power BI Parquet connector.
Apache Spark in the Lakehouse: rebranding from Synapse Spark?
It doesn’t take more than a simple Hello World to demonstrate that the Spark experience in Fabric is drastically better than what we had in Azure Synapse with Synapse Spark. Creating a new Lakehouse in Fabric takes a few seconds and running your first Notebook on that Lakehouse doesn’t take much longer either. The start-up time of the Spark session is a fraction of what it typically takes to boot up a Spark cluster in Synapse Spark or Databricks.
One of the cool features that Databricks had but was still missing in Synapse Spark, has now also arrived in Fabric : High Concurrency Mode. This allows you to share a Spark session between multiple Spark Notebooks. So even after the very short start-up time, the next notebook you’ll be running doesn’t even have to take that short hit.
It also seems that the Spark Runtime in Fabric features more and newer libraries than what Synapse Spark has to offer.
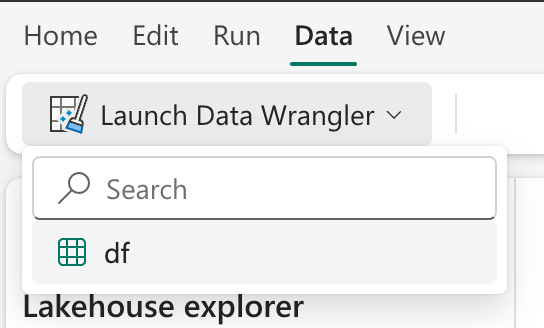
The Notebooks experience itself is also quite different from what you have available in Azure Synapse. Things like the Data Wrangler are very welcome additions. You can now even just add resources to your Notebooks like Python wheel files.
So, once again, just a rebranding? Well, Microsoft probably started at what they had in Synapse Spark. But the version in Fabric is so much better and drastically different that I wouldn’t call it a rebranding. It’s a completely new experience.
T-SQL: rebranding from Synapse Serverless SQL or Dedicated SQL?
Now we’ve arrived at my favorite part of this rebranding misconception. Why? This is the part where your jaw will drop.
Microsoft reused the Synapse branding from Azure Synapse Analytics for the T-SQL experiences in Fabric. We have 2 of them:
- the Lakehouse T-SQL Endpoint: a read-only version of the Delta Lake tables in your Lakehouse on OneLake
- the Data Warehouse: a read-write version of Delta Lake tables on OneLake
Both are exposed through a single connection string as individual databases and offer a high (but incomplete ) level of compatibility with the regular T-SQL syntax you already know.
I wouldn’t blame you if you thought the Lakehouse is just Synapse Serverless SQL and the Data Warehouse is just Synapse Dedicated SQL. While the feature sets may be similar, you couldn’t be further from the truth.
It’s time to introduce Polaris again. Polaris is a new query processing engine that Microsoft built from the ground up. The major part of this engine was built in the previous decade and the work was presented at the yearly VLDB conference in 2020. You can download the paper here .
So… 3 years ago?! Yes! I’d highly recommend reading the paper. One thing you might notice is that it also mentions a storage system with project name Fido. Microsoft never shared any details about Fido, but it seems that this project wasn’t completed at the time and that they decided to go through with just the Polaris engine.
The paper mentions an internal Microsoft report as reference for Fido:
Report, Microsoft. FIDO: A Cloud-Native Versioned Store With Concurrent Transactional Updates. 2020.
One of the new products in Azure Synapse Analytics was the Serverless SQL Pools. This was the first result of the Polaris engine being used in production. But it was still a very limited version of the engine. It only supported a subset of the T-SQL syntax and it was read-only.
We now see the full roll-out of Polaris in Microsoft Fabric. The Data Warehouse is completely built upon Polaris, while Synapse Dedicated SQL Pools were built on the Parallel Data Warehouse engine from the early 2010s.
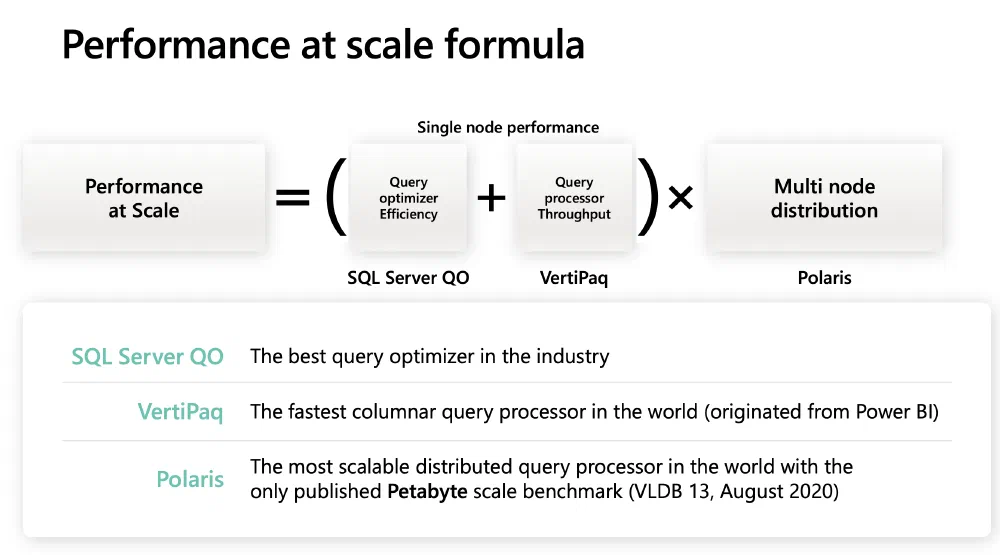
In the video above, Bogdan mentions the Polaris engine. In the slide above, from a presentation Bogdan gave at Data Platform Next Step 2023, you can see how Fabric’s T-SQL engine works with Polaris. Fabric seems to be using a distributed cluster of nodes. Every node has a full installation of the SQL Server Query Optimizer and uses VertiPaq to read the Delta Lake tables from OneLake. Then, Polaris is used with its intelligent Data Cell Distribution system to distribute the workload across the nodes.
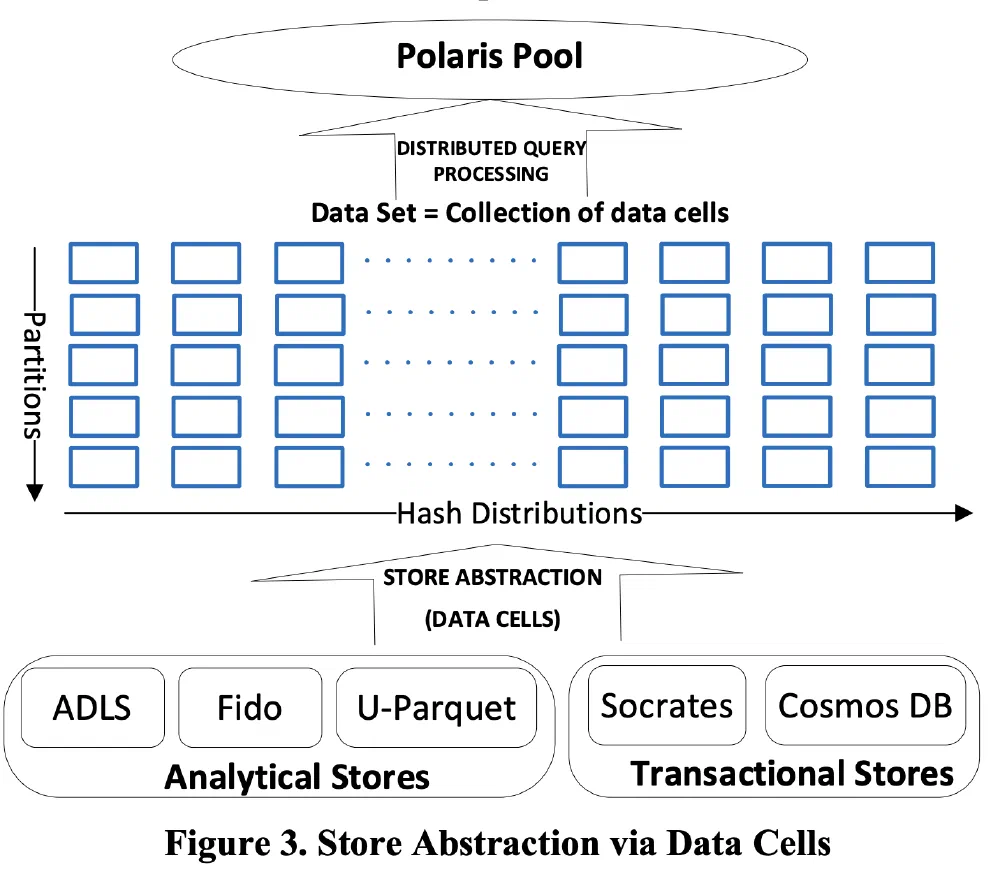
If any reader would have more information on Fido and what happened with that project, I’d be super interested in hearing more about it as these things genuinely interest me 🙂
KQL: rebranding from Data Explorer?
Azure already had lots of different options for streaming data analytics:
- Azure Data Explorer Clusters
- Synapse Data Explorer Pools
- Azure Stream Analytics
For ingestion of the data, we have the following options:
- Azure Event Hub
- Azure IoT Hub
- Azure Event Grid
From the Power BI side, we also had Streaming Dataflows in preview for a while.
And now with Fabric, we have the following new streaming-focussed features:
- KQL Database & KQL Queryset
- Eventstream
How do you know which one you should use? Let’s answer the following questions:
- Do you want to integrate your streaming data with other data in Fabric or do you not have any other specific requirements?
👉 KQL Databases in Fabric - Do you want a stand-alone and simple solution for creating aggregates of the streaming data?
👉 Azure Stream Analytics - Do you want to fine-tune your spending and choose a specific hardware configuration to analyze your streaming data?
👉 Azure Data Explorer Clusters - Do you want to analyze the streaming data in your existing Synapse environment?
👉 Synapse Data Explorer Pools - Do you want to use a GUI to transform your streaming data and only require visualization in Power BI?
👉 Streaming Dataflows in Power BI
Are the KQL Databases more than just a rebranding? It seems to be a layer on top of the Data Explorer Pools/Clusters that allows you to query the data using KQL. But, next to that, you can also easily combine the streaming data with other data in Fabric Lakehouses through the use of Shortcuts. In this case, I’d lean more towards calling it a rebranding, but with new and very worthwhile features on top.
Conclusion
So, overall, is Fabric just a rebranding? I hope that I’ve managed to convince you that it’s clearly not. Of course, no need to reinvent the wheel or ignore what was there before. Microsoft took some bits and pieces from existing technologies and used those in Fabric. Wouldn’t you? But to put it down as just a rebranding would be incorrect. It’s a completely new experience that is much better than what we had before. Under the hood, we can identify lots of completely new features and engines. It’s a revolution, not an evolution. And I’m very excited to see where this is headed.
