data engineering
I just took the new Fabric DP-700 Data Engineering Exam: here's what you should know

I took the new DP-700 exam, released just hours ago in beta, and I’m here to share my experience along with some tips to help you prepare.
Fabric: Lakehouse or Data Warehouse?

There are 2 kinds of companies currently active in the Microsoft data space: those who are migrating to Microsoft Fabric, and those who will soon be planning their migration to Microsoft Fabric. 😅 One question that often comes back is Should I focus on the Lakehouse or the Data Warehouse? Let’s answer that in this post. I can already tell you this: you’re asking the wrong question 😉
Is Microsoft Fabric just a rebranding?

It’s a question I see popping up every now and then. Is Microsoft Fabric just a rebranding of existing Azure services like Synapse, Data Factory, Event Hub, Stream Analytics, etc.? Is it something more? Or is it something entirely new? I hate clickbait titles as much as you do. So, before we dive in, let me answer the question right away. No, Fabric is not just a rebranding. I would not even describe Fabric as an evolution (as Microsoft often does), but rather as a revolution! Now, let’s find out why.
Fabric end-to-end use case: Data Engineering part 2 - Pipelines
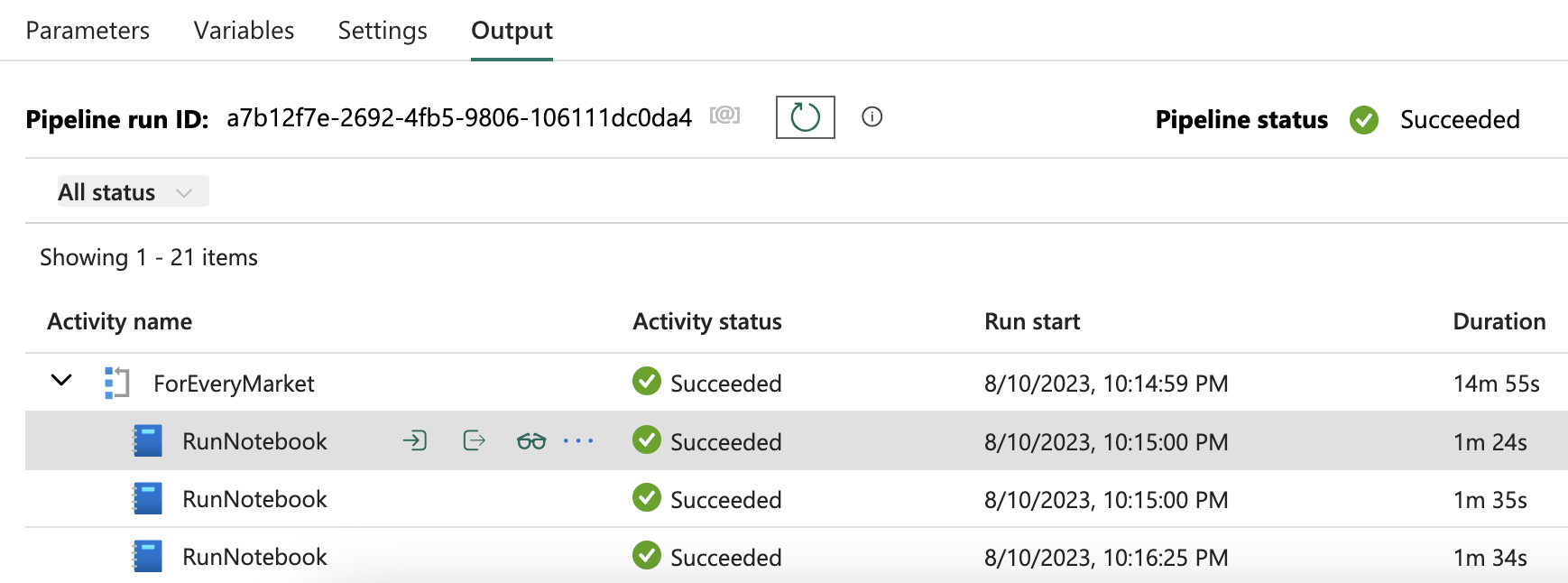
Welcome to the third part of a 5-part series on an end-to-end use case for Microsoft Fabric. This post will focus on the data engineering part of the use case. In this series, we will explore how to use Microsoft Fabric to ingest, transform, and analyze data using a real-world use case.
Fabric end-to-end use case: Data Engineering part 1 - Spark and Pandas in Notebooks
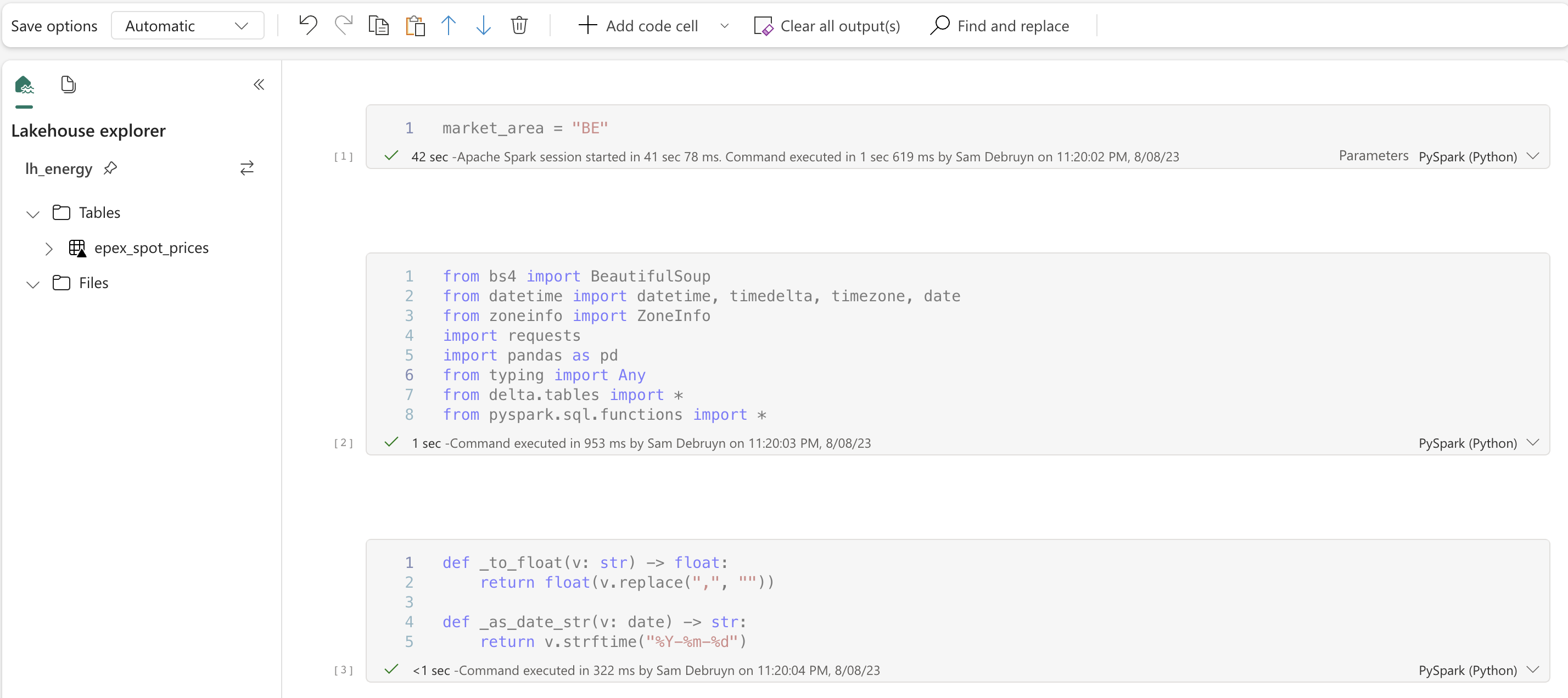
Welcome to the second part of a 5-part series on an end-to-end use case for Microsoft Fabric. This post will focus on the data engineering part of the use case. In this series, we will explore how to use Microsoft Fabric to ingest, transform, and analyze data using a real-world use case.
Fabric end-to-end use case: overview & architecture
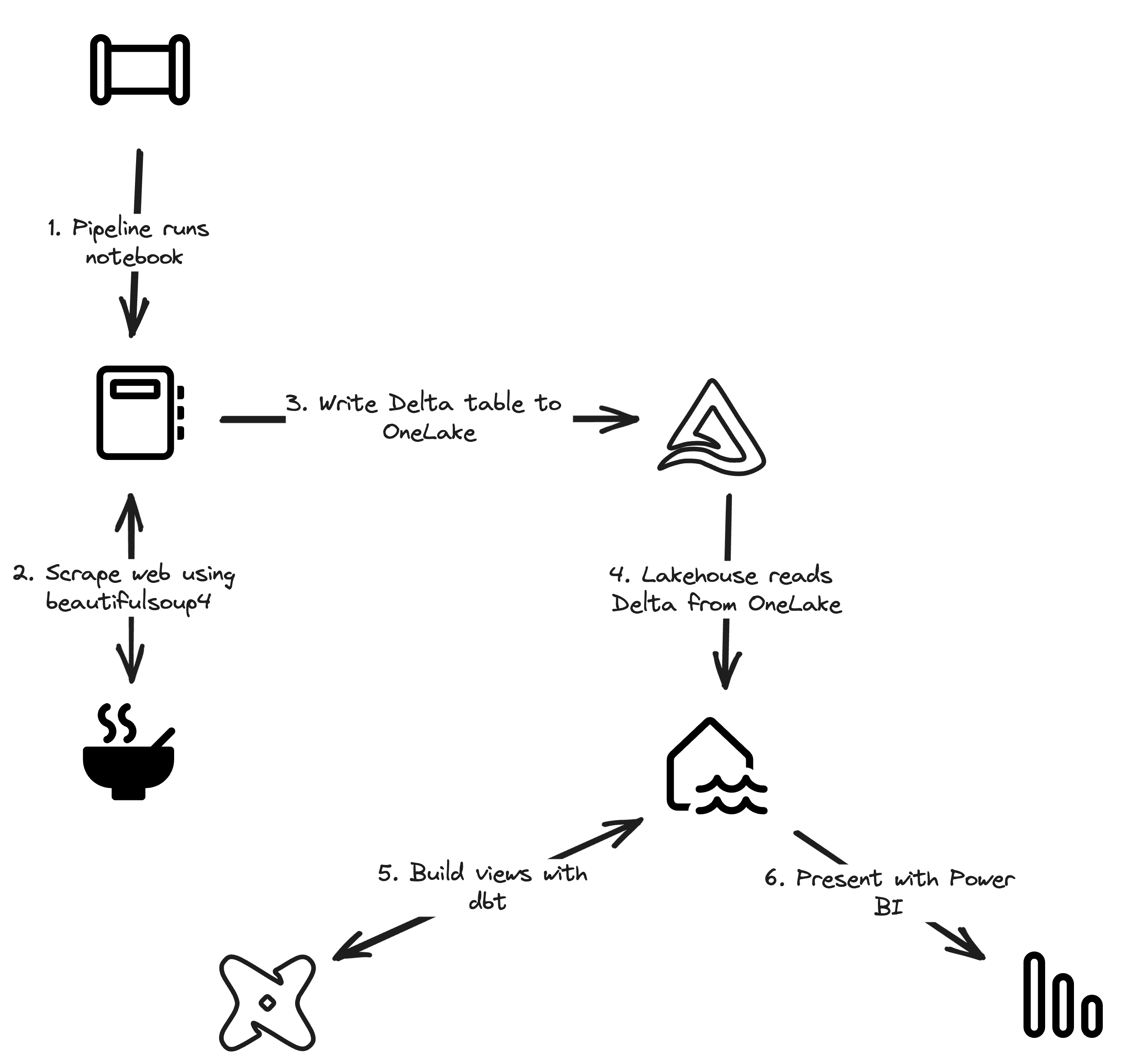
Welcome to the first part of a 5-part series on an end-to-end use case for Microsoft Fabric. This post will focus on the architecture overview of the use case. In this series, we will explore how to use Microsoft Fabric to ingest, transform, and analyze data using a real-world use case.
Let Fabric teach you how to code with Data Wrangler
I’m going to be honest with you. I’m bad at writing Pandas data transformation code. Throughout the years I mostly focussed on the Spark APIs in Scala and PySpark, SQL, dbt, and some others, but I find the Pandas APIs usually just confusing and hard to read. I don’t like the black box magic and lock-in of low-code solutions either. Did you know that Microsoft Fabric has the perfect middle ground for this? It’s called Data Wrangler. Let’s dive in!
Migrating Azure Synapse Dedicated SQL to Microsoft Fabric

If all those posts about Microsoft Fabric have made you excited, you might want to consider it as your next data platform. Since it is very new, not all features are available yet and most are still in preview. You could already adopt it, but if you want to deploy this to a production scenario, you’ll want to wait a bit longer. In the meantime, you can already start preparing for the migration. Let’s dive into the steps to migrate to Microsoft Fabric. Today: starting from Synapse Dedicated SQL Pools.
Microsoft Fabric's Auto Discovery: a closer look
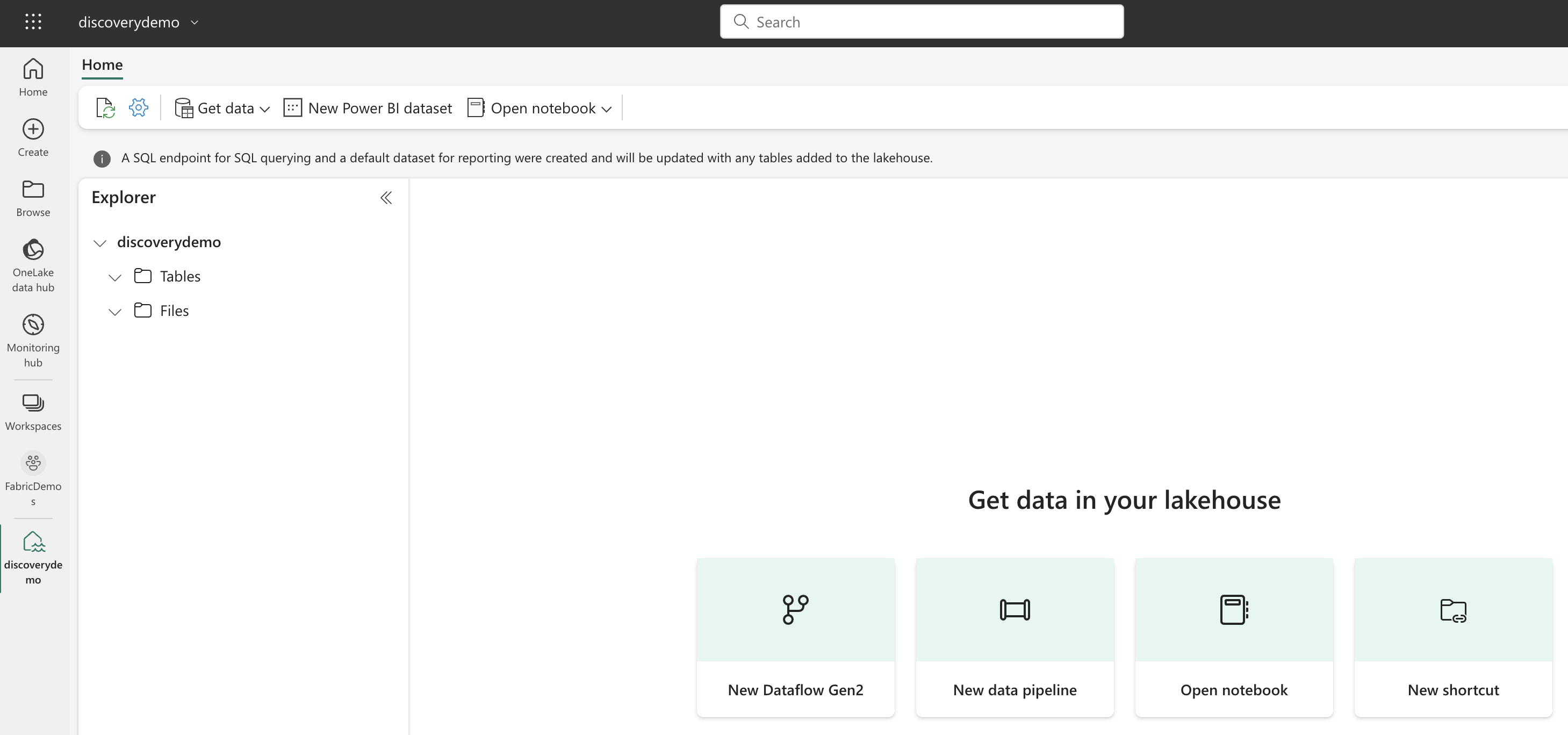
In previous posts , I dug deeper into Microsoft Fabric’s SQL-based features and we even explored OneLake using Azure Storage Explorer . In this post, I’ll take a closer look at Fabric’s auto-discovery feature using Shortcuts. Auto-discovery, what’s that? Fabric’s Lakehouses can automatically discover all the datasets already present in your data lake and expose these as tables in Lakehouses (and Warehouses). Cool, right? At the time of writing, there is a single condition: the tables must be stored in the Delta Lake format. Let’s take a closer look.